Jeg hørte ordformen for første gang da Sandra Borch annonserte sin avgang 19.01.2024. Hun tok det forslitte uttrykket «på det nåværende tidspunkt» og puttet det inn i Lavangen-dialekten og skapte formen «nåværandese».
Presens partisipp av verb ender i bokmål på «-ende» («nåværende, sittende»), og i nynorsk på «-ande) («noverande, sitjande»). Borch brukes a-varianten, og hun har også med den s-en som en finner i mange dialekter (ståandes, gåandes).
Ordforma brukes som adjektiv og stilles foran substantivet det står til. Strukturen er den samme som i «sovende barn, løpende villsvin».
Substantivfrasen står i bestemt form. Dette gjøres ved å stille adjektivets bestemte artikkel «det» foran frasen. På bokmål heter det jo «det nåværende tidspunkt». Når slike uttrykk står i bestemt form, for adjektivet tillagt endelsen «-e» slik at «en avgått minister» blir til «den avgåtte ministeren». Siden «nåværende» allerede ender på «-e», lar det seg ikke gjøre å legge til en ekstra «-e» på norsk, så uttrykket forblir «det nåværende tidspunkt».
I «den avgåtte ministeren» står substantivet «ministeren» bestemt form. I en del faste uttrykk i norsk kan imidlertid substantivet stå i ubestemt form, jf. uttrykk som «den norske løve, den fortapte sønn». Slike uttrykk oppfattes oftest som alderdommelige, og en finner et lite antall nye konstruksjoner med denne strukturen.
Deretter plasseres uttrykket «det nåværende tidspunkt» etter preposisjonen «på»: «på det nåværende tidspunkt».
Borch opprettholder enkelt bestemmelse, men gir ordet «nåværende» en dialekt form: «nåværandes». Siden denne formen ender på «-s», gir det rom for en etterfølgende «-e», og dermed markeres adjektivets bestemte form eksplisitt, og vi får formen «nåværandese», som går inn i «på det nåværandese tidspunkt». Dette kan høres etter 5:13 i denne videoen.
13 sekunder seinere (5:26) blir samme uttrykk gjentatt, men nå i en litt annen form; «på nåværandes tidspunkt», en form som er tilpasset standardstrukturen.
Jeg publiserte nylig boka Gustav Strømsvik – maya-arkeologen fra Rødøy. Boka er omfattende og i den avsluttende prosessen ble det nødvendig å utelate deler av noenl kapitler. Noe av dette publiseres derfor her.
Mayaenes skrift [1]
Da spanjolene erobret Maya-riket på 1500-tallet, tvang de urfolkene i området til å konvertere til kristen tro og til snakke og skrive på spansk. Dermed brente de alt de fant av skriftlig materiale på papir av bark. Dette var djevelens verk, og det måtte bort! Den spanske undertrykkingen førte til at kunnskap om glyfer og skriving gikk tapt, men noe dokumentasjon har overlevd. Et dokument som har spilt en viktig rolle er Relación de las Cosas de Yucatán[2] – Opptegnelser om saker i Yucatán – skrevet av Diego de Landa Calderón (1524‒1579) omkring 1566. Mayaforskeren Michael Coe sier at boka ikke bare en gullgruve med hensyn på de historiske forholdene som dokumenteres, men at den også er nøkkelen til forståelse av mayaskrift. På den annen side er de Landa ingen helgen. I 1562 organiserte han brenning av tusenvis av bøker. I dag finnes det bare fire originalmanuskripter fra førkolumbiansk tid som er bevart. De er kjent som Dresden-, Madrid-, Paris- og Grolier-codexene. de Landas manuskript og Dresden Codex er avgjørende bidrag i den senere dekoding av mayaenes kalendersystem og deres avanserte forståelse av astronomi og matematikk.
I 1832 fikk den amerikansk forskeren Constantine Rafinesque (1983‒1840) tilgang til fem sider av Dresden Codex, og ut fra dette kunne han utlede mayaenes tallsystem. Han dokumenterte at prikkene og strekene i inskripsjonene stod for tall der en prikk representerte «en» og en strek «fem». To prikker var derfor ”to”, mens to prikker og en strek var ”sju”. Senere funn viste at at mayaene allerede før vår tidsregnings begynnelse hadde et symbol for null. Det matematiske begrepet «null» dukket opp ikke i Vest-Europa før i det 12. århundre.
Neste sprang i forståelsen av mayaskriften skjedde 50 år senere da Ernst Förstemann (1822‒1906), en matematikkinteressert bibliotekar, ved hjelp av nedtegnelsene i Dresden Codex klarte å tyde mayaenes astronomitabeller i tillegg til å dechiffrere kalendersystemet. Dette gjorde det mulig å konvertere mayadatoer til den moderne vestlige kalender, og slik kunne man følge utviklingen i de ulike byene i mayariket.
Den engelske diplomaten Alfred Maudslay var oppslukt av mayaenes liv og historie og satte seg fore å dokumentere mest mulig av sivilisasjonens arkitektur og kunst. Han dro rundt med et et stort glassplate-kamera og tok svært detaljert bilder av byggverk og skulpturer, deriblant klare nærbilder av glyfer – som inskripsjonene og så kalles. Han lagde også avstøpninger i papirmasse av relieffer, og fra disse ble det laget nøyaktige tegninger. På denne måten bidro Maudslay til å bygge opp det første systematiske korpuset av inskripsjoner etter de store ødeleggelsene, og slik kunne forskere utenfor mayaområdet få tilgang til materialet, noe som bidro til videre utvikling av mayaforskningen.
Stele N, Copán 1885. Foto: Alfred Maudsley
På 1930-tallet var den britiske forskeren J. Eric S. J. verdens fremste ekspert innen studiet av mayaglyfer. Han og Gustav Strømsvik ble kolleger i Chichén Itzá, og de to hadde nært samarbeide i mange år framover. Thompson dechiffrerte tegn knyttet til kalenderen og astronomi, i tillegg til å identifisere nye ord. Thompson hovedhypotese var at de fleste symbolene i mayaskriften representerte ord eller ideer, men dette kom til å lede galt avsted. For eksempel inkluderte glyfen for «vest» et kjent symbol for sol og et uidentifisert symbol som lignet en lukket hånd. Thompson hypotese var at hånden symboliserte «ferdigstillelse», og følgelig ble glyfen «vest» tolket som «solens ferdigstillelse.» Gjetningen var plausibel, men gal.
Thompson hypotese var at mayasivilisasjonen primært hadde sitt fokus på tid og tidsforløp, og at alle andre skriftlige uttrykk enn de som var knyttet til datoer og astronomi, var uttrykk for mystikk som mayaene utøvde for å komme i kontakt med sine guder. Thompson hadde en dominerende posisjon innenfor denne delen av mayaforskningen i lang tid, mens siden hypotesene hans var gale, førte dette til at studiet av glyfer viste lite utvikling i årene som fulgte.
Mens det var få framskritt i studiet av glyfer i den vestlige verden, gjorde en russisk lingvist i Moskva noen banebrytende funn. Da den russiske hæren marsjerte inn i Berlin i 1945 var den ung russeren Jurij Valentinovitsj Knorosov en av offiserene. I ruinene av nasjonalbiblioteket fant han en bok som hadde overlevd brannen, det var en svart-hvitt gjengivelse av Dresden-, Madrid- og Paris-codexene. Boka var fascinerende, og interessen vokste da han leste en artikkel som konkluderte med at maya-glyfene ikke lot seg dekode. Dette tok han som en utfordring og etter å ha tatt en grad i lingvistikk ble han den eneste russeren innenfor dette forskningsfeltet, som var dominert av J. Eric S. Thompson. I 1952 foreslo Jurij Knorosov at de enkelte symbolene i glyfene representerte språklyder på samme måte som bokstaver gjør. Knorosov mente at skriftspråket hadde alt for mange glyfer til å være et ekte alfabet, men samtidig for få til at hver glyfe kunne symbolisere et helt ord.[3] Knorosovs hypotese var at mayaenes skriftspråk var bygd opp rundt en kombinasjon av disse elementene, og han konkluderte med at siden ordet for «vest» var chikin og ordet for sol var kin, representerer hånden øverst i glyfen stavelsen chi. Dette var en helt annen hypotese enn Thompsons, som i 1962 gav ut A Catalog of Maya Hieroglyphs[4] som var da var den mest komplette oversikten over tegn. To amerikanske forskere, Michael og Sophie Coe, hadde da allerede fattet interesse for Knorosovs synspunkter og publiserte hans artikler i USA på slutten av 1950-tallet.[5] Hadde de ikke gjort det er det fare for at den den kalde krigen ville ha holdt synspunktene utilgjengelige i mange år framover.
Mayaenes skriftsystem var lenge en gåte. Deler av den, for eksempel tallsystemet ble forstått tidlig, men det er altså først i vår tid at man har fått oversikt skriftsystemet og har kunnet tyde det. Skriften hviler på tre systemer, nemlig ideogram – en avbildning av et begrep, en idé eller en handling, slik man finner det i kinesisk skrift, stavelser som man finner i japansk, og tegn for enkeltlyder, altså bokstaver slik en for eksempel finner det i det latinske alfabetet, som ligger til grunn for hvordan vi skriver norsk. Ideogrammer kan også være en direkte avbildning av et objekt, et såkalt piktogram. I mayaenes skriftspråk står følgende tegn for «jaguar», og en ser at det er en avbildning av en jaguar. Ordet for jaguar er balam.
Ordet for «himmel» er chan, og det symboliseres med tegnet nedenfor. Det er vanskelig å peke på konkrete sider ved symbolet som indikerer at det avbilder en «himmel». Slike symboler betegnes som ideogram[6].
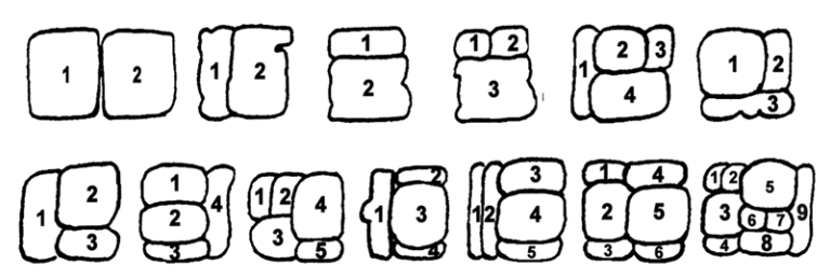
Ordet for «jaguar» ‒ balam ‒ har vi allerede skrevet med latinske bokstaver som indikerer hver enkelt språklyd i ordet: b-a-l-a-m. Dette er alfabetskrift. Mayaene kunne også skrive ned lydene i ordet, men de brukte et såklat syllabisk system.[7] Det vil si at de delte ordet opp i enkeltstavelser, og hver stavelse fikk et eget tegn. På denne måten skrives balam slik:
De skriftlige uttrykket er tre tegn som er skrevet tett sammen. De symboliserer fra venstre mot høyre de tre stavelsene ba – la – ma, der ma er plassert til høyre under la. Ordet for «jaguar» er ikke *balama, men balam, og det kommer vi fram til når vi vet at det er en regel som sier at vokalen i den siste stavelsen skal strykes: balama → balam. Hver for seg ser de tre symbolene slik ut:
ba:
la:
ma:
En kan legge merke til at utformingen på tegnene varierer noe. Dette skyldes delvis at utformingen endres når tegnene skrives sammen, men også at utformingen av tegnene varierte avhengig av hvem som skrev, i hvilken epoke tegnet ble skrevet og på hvilket sted det ble skrevet.
Det finnes også flere tegn for hver stavelse slik at glyfer med samme betydning kan ha ulik grafisk utforming. Dette kan på en måte sammenlignes med at vi på norsk har ulike skrivemåter for et og samme ord («tunnel – tunell»). Grunnregelen var at tegnene skulle skrives parvis to og to nedover, men det er mange eksempler på at rekkefølgen på glyfene varierer.
I tillegg kan de varierere i størrelse og form, og de kan i ulik grad være bygd inn i andre glyfer, som når tegnet for mo kombineres med tegnet for lo til ett nytt tegn, mo-lo.[8]
molomo-lo
Selv om det er rundt 1000 forskjellige symboler i skriftspråket, regner man med at en skriftlærd mestret 300 til 500 tegn. Selv om talespråket har fem vokaler og nitten konsonanter, finnes det faktisk 200 stavelsestegn. Dette skyldes at man har flere kombinasjonstegn for konsonanter og vokaler, og at en enkelt lyd kan være representert av flere forskjellige tegn. Stavelsen ba kunne for eksempel representeres av disse tre tegnene:
I tillegg utviklet skriftspråket seg over tid. I noen tilfeller ble det laget symboler som var mer estetisk tiltalende. Dette kunne skje ved at de skriftkyndige kombinerte tegn eller forenklet dem. Eldre symboler som representerer hele ord ble også bevart fordi de hadde høyere status enn stavelsymboler, noe som kan forklares med ærbødighet for tradisjon, språkets hellige natur og ønsket om å gjøre teksten så tilgjengelig som mulig for flest mulig lesere.
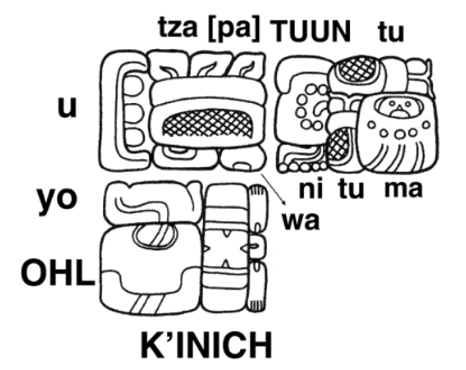
Kompleksiteten i et skriftlig uttrykk ser en i følgende inskripsjon fra Quirigua[9]. Ved å følge nøkkelen som er oppgitt i figuren og så identifisere motsvarnede element i figuren, ser en strukturen i det skrevne uttrykket som i norsk oversettelse vil være omtrent ”Tutuum Yohl K’inich setter ned steinen”.[10]
[5] Coe, Michael (1992) Breaking the Maya Code, London: Penguin. s. 156-158.
[6] I dagliglivet omgir vi oss med et stort antall piktogram og ideogram. På toalettdører ser en ofte piktogrammer som indikerer hvor damer og menn skal gå. Trafikkskilt er en blanding av piktogram og ideogram. Bildet av en gående person på et gangfelt er konkret og og let forståelig piktogram, mens ideogammet med en trekant med spissen ned, som indikerer vikeplikt, ikke har noen komponent som indikerer at man skal stoppe. Her er det en sosial konvensjon som foreskriver hvordan skiltet skal forstås.
[7] Ordet kommer fra fra gresk syllabe som nettopp betyr «stavelse».
Jeg ryddet i gamle papirer forleden og kom over en artikkel jeg skrev i studentavisa Kjæftausa i 1977 (12. årgang nr. 4). Jeg fulgte da forelesninger i norsk grammatikk ved NLHT, i dag NTNU, og var tydeligvis irritert over eksempelmaterialet som ble brukt i forelesningene. Jeg ble innkalt til samtale med den navngitt foreleseren. Samtalen foregikk i rolige former, men det var nok litt ubehagelig å bli «outet» på denne måten. På den annen siden var studentavisas opplag utbredelse svært begrenset. Innlegget er inspirert av en artikkel av Else Ryen i boka Språk og kjønn. Artikkelen er trykket som den stod, altså uten rettelser. Uris perspektiv er et annet og mer vidtfavnende, men det faktum at hun skriver om dette i dag, viser at kjønnsbalansen i språk ennå ikke er oppnådd.
Kjønna i grammatikken
«… det er et slags kvinnelig fraver i språket … språket gjenspeiler virkeligheten … språket vårt viser kvinnens underordna stilling i et samfunn som fortsatt har mange patriarkalske trekk.? (Else Ryen i «Språk og Kjønn,» Novus, Oslo – 76, s 72,78).
Med desse orda som leiesnor gjekk eg i gang med å analysere eit objekt som tør vere kjent for ein del norskstudentar: Amanuensis Rønhovds forelesningskonsentrat i grammatikk utgitt i tre hefte haust/vår -75/76. Eg ville prøve å finne korleis eksempla fordelte seg på kjønn, og kva for rolle aktørane spela. Nokre ord om metoden: Av alle eksempla i hefta fall ein del bort fordi dei var irrelevante med omsyn til kjønnsbestemming (hest, fly), eller nøytrale med omsyn til det same (vi, dei). Av dei 396 som vart igjen, var det om lag 97 syntagme og 299 heilsetningar.
Av syntagma har 5 feminin kjerne (5,2%), 92 har maskulin kjeme (94,8%). Forholdet her er altså 1:18,4. Kjønnsfordelinga vart registrert med omsyn til ulike forhold og her er resultatet. Heilsetningane: Vi finn 358 kjønnsmarkeringar i dei 229 eksempla. Av desse er 34 (9,5%) fem., og 324 (90,5) mask. Vi finn 20 fem. subjekt (7,5%), 247 mask. (92,5%), 14 fem. i oblik kasus (15,4%) 77 mask. (86,4%).
La oss dissekere litt meir og sjå den kjønnsmessige fordelinga blant substantiva (NB: Berre dei som kunne kjønnsbestemmast slik som «mann» og (sjeldent) «kvinne».) Vi finn 23 fem. substantiv (6,0), 360 mask. (94). Blant pronomen 12 fem, (5,4), 211 mask (94,6). Forholdstalet er: 1:17,5. (Jfr. «Vi är halften » der det blir påstått at forholdstalet er 50:50 – og det er vel sant?)
Kva gjer aktørane? Det vanlege hadde eg nær sagt. Vi ser inn i ein verden lik våres, der funksjonen er relatert til kjønn. Vi finn aktive menn som eier, reiser, underviser, får overrakt medaljer, som er prest, lærer, geni, dyktig pedagog, ein Bjørnson, ein ubrukt Tell, ein Byron osv. osv. Vi finn kvinner som går rundt i en stilig kjole, stramt ettersittende som en hanske, mens de ser «utfordrende» på ham. Hovedinntrykket er likevel at dei rett og slett ikkje er til stades.
Utvalget eg har gjort, er kanskje skeivt, det finst sjgølvsagt andre ting blant eksempla. Men dei kan ikkje endre på heilskapen. Jfr. tala ovanfor.
A dømme forfatteren nord og ned vil vere galt – hans medvit er del av ein større heilskap som er sams for mange i språk – samfunnet. Men i ei tid då dei sosiale vanane er i ferd med å bli endra bør vi og bruke språket for å vise kva vi må forandre oss frå.
På skolen fikk vi fort inntrykk av at bokmålet var langt bedre enn den lokale dialekten, iallfall når det gjaldt skriftlig arbeid. Når vi skrev i norsktimene, ble dialektord korrigert med bokmålsformen som mal. «Mætt» skulle skrives «mett», og «dett og mett» ble til «ditt og mitt». Bøyningsendelser måtte byttes ut, og «bokæ» ble gjerne til «boken» selv om «boka» også var mulig. Vi ble ikke undervist i radikale bokmålsformer med -a-endelser. Noen ord var det ikke plass til i bokmålet, så «sny» og «svang» måtte vike plassen for «snø» og «sulten». At «e e …» var umulig å skrive i en setning, fikk vi vite tidlig. Det skulle jo være «jeg er …». Vi lærte etter hvert, og etter hvert brukte ikke læreren rødblyanten så ofte.
Men bokmålet er langt fra plettfritt. Som vi har sett tidligere, er det mange ord i dialekten som ikke finnes i Bokmålsordboka. I tillegg har bokmålsgrammatikken hull som grammatikken i sandnessjø-dialekten ikke har. Tenk deg følgende situasjon: Du ser en grå bil er inneparkert av en annen bil som er rød av farge. Du ser også to grupper mennesker som står i nærheten av bilene. Eieren av den grå bilen går bort til den ene gruppen, peker på den røde bilen, og du hører henne stille spørsmålet: «Er den deres?». Hvordan forstår du spørsmålet? Spør hun om den tilhører en person i gruppen hun snakker til, eller en person i den andre gruppen? Tenk i 10 sekunder før du leser videre.
Det er faktisk ikke mulig å vite hvilken gruppe eieren av den grå bilen forhører seg om. Bokmålsordet «deres» brukes både i 2. person flertall (de som man snakker til) og 3. person flertall (de som man snakker om). For å uttrykke seg entydig kunne hun ha valg en annen form og sagt «Tilhører bilen dere eller dem?» eller «Er det de eller dere som eier bilen?»
I Sandnessjøen ville de ikke ha vært nødvendig å omformulere spørsmålet. Det ville ganske enkelt ha vært «Er dæ bilen dåkkers?» eller «E dæ bile deres?». Eller hvis man slår sammen spørsmålene: «Er dæ bilen dåkkers elljer deres?» Når man ser bokmålsversjonen av dette – «Er det bilen deres eller deres?» – ser man tydelig hva bokmålet mangler.
I Språknytt 3/17 kalles dette for en grammatisk defekt i bokmålet. Artikkelen understreker at de to formene som vi finner i vår dialekt, «dåkkers» og «deres», har sin parallell i alle norske dialekter. Der finner man på den ene siden blant annet «døkkers, dåkkers, deres», og på den andre siden «deires, doms, dæmmers, dems».
Skillet finnes også på nynorsk (dykkar/dokkar – deira»), på «svensk («er – deras») og på dansk («jeres – deres»). Også andre europeiske språk har det samme. Leseren kan jo selv finne ut hvordan dette ville være på engelsk, spansk eller tysk.
Men på bokmål finnes ikke dette i skillet, verken i skrift eller i talemålet hos dem som legger bokmålet til grunn.
Bannskapen har forandret seg siden jeg begynte å bygge opp mitt vokabular av «stuggord» i ungdomstida. Alle ordene var for norske å regne, men i dag hører en engelsk «fuck, shit, asshole, bitch», gjerne iblandet de klassiske «faen, satan, helvete».
Jeg har inntrykk av at dagens vokabular er ganske avgrenset. Variasjonbredden var nok større før når det gjelder ordtilfang. komposisjon og styrke. Dette tillot folk å nyansere bannskapen mer, og det fantes «spesialister» i faget som virkelig kunne få språket til å blomstre ved å konstruere finurlige og maleriske vendinger. En episode fra Saltdal knyttet til reparasjon av en vaskemaskin var så sterk at den er omtalt i Nordnorsk kulturhistorie!
Bannskapen brukes til å til å lette på trykket og til karakterisere situasjoner, ting og personer. Kraften i uttrykkene kan graderes på ulike måter, og når en «spesialist» tok alle virkemidler i bruk, kunne produktet nærme seg poesi. Jeg skjønner at det er alvor når jeg hører «Dæven hannj så brennjsteike innjst innji dæ svartsviddje hælvete!!!». Den bakenforliggende årsaken kan gjerne være et kraftig hammerslag som traff tommelen.
Bannskapen kan sorteres i ulike grupper. Det norske vokabularet tilhører tre livsområder: kjønnsorganer, avføring og religion. I andre språk trekker man også inn den nærmeste slekt, og da helst «mor», og det engelske «motherfucker» har forlengst gjort sitt inntog.
Jeg lar kjønnsorganene være i fred og ser heller se litt på bannskapsvokabularet. Der er jo djevelen hovedpersonen. I litt mildere ordelag er han også kjent som «hannj Gammel-Erik, hannj meisk,» eller «hannj pærkjel». Disse termene kan godt brukes om personer, men en kan gi litt mer gass og beskrive vedkommende som «en rein dævel / dækel / jævel».
Graderingen kan vi også observere når et litt blekt «fakern» eller «fakern ta» forsterkes til «fanden» og i neste trinn «faen». På samme måte kan et litt svakt «dykan døysen» oppgraderes til «dæsken» som igjen kan forsterkes til «dæven» som i sin tur kan oppgraderes til «dæven hannj steike».
«Hannj tykje» blir fremdeles påkalt nordpå, og navnet brukes gjerne som beskrivende førsteledd i «tykjepelk og tykjebran». Alle vet at en «nellik» er noe helt annet enn en «tykjenellik». Tilholdsstedet til «han tykje» var selvsagt i «hælvete», og stedet kunne utmales med ord som «heitaste / innerste» om nødvendig. Ting som hører til der, benevnes selvsagt som «nån hælvetes saker» eller «nån helsikes saker» hvis en er litt mildere stemt. Dårlig verktøy og annet kunne bli benevnt som «mannjskit» hvis sinnet ikke var så sterkt. Ble irritasjonen større, ble det ofte snakk om «nå jævlæ førbannjæmakt» og så kunne en øse på med den bannskapen en hadde tilgjengelig.
Ferdigheter kunne spesifiseres med «beiskædø / bæskandø / bæskantullj /piskædausn /piskantullj». Sammenhengen viste om dette var negativt eller positivt ment: «Han va piskantullj me ikkje ufale når hannj drakk!» Men på den annen side var han «piskædausn me go te å slå på trommæ!». Kommentarer til hendinger kunne også innledes med små salver som «Beiskædø, ha du hørt at …?» og så kom den livfulle beskrivelsen av hva som hadde skjedd..
Oppfordringer kan modifiseres på ulike måter. Verb forsterkes med «pinædø, bætterdø, bætterjoL» som i «No må du bætterjoL kom!». Andre ord står foran adjektiv som i «Han va bættele / jævla / førbannjæ stærk i går! Ord som «hælvetes / satans» kan brukes med substantiv, adjektiv og adverb: «en hælvetes fyr, han var satans kvekk i hauet» og «ho sang så hælvetes fint».
Ansikt til ansikt med en person kunne man karakterisere vedkommende ved å starte tiraden med «dinnj» eller «dett»: «Dinnj førbannjæde idiot» eller «dett inntørkæ trehau». Dette er kanskje mer utskjelling enn bannskap, men det er fort gjort å gjøre utsagnene atskillig sterkere ved å innkalle bannskapsvokabularet.
Ordenes opphav lar jeg ligge, og spør heller: Hvor lærte jeg dette? Mye ble nok plukket opp i samvær med eldre gutter, men det er ingen hemmelighet at vokabularet til mitt faderlige opphav ikke var til å kimse av, så jeg har nok overtatt noen gloser fra ham. Min mor var langt mer beskjeden med sine «huff» og «tvi vøre». Hvis hun mente at jeg var «alljdeles førrhærd», for ikke å snakke om «besætt», var beskjeden klar: «Fisj være! Gå og vask de i munjn!» Gudene vet hva hun ville ha sagt om hun kunne lese det jeg har skrevet her.
I 6. klasse fikk vi fru Skarpaas som lærer. Hun var østlending og kunne ikke unngå å legge merke til de mange og rare dialektordene vi brukte. Hun ble invitert av NRK til å fortelle om sin lærergjerning i nord og kom da også inn på språklige forhold. Et av ordene hun hadde stusset over var «klar». Slik hun brukte ordet, betydde det enten «forberedt, parat» som i «Jeg er klar til å gå på fjellet». Det kunne også være en beskrivelse av hvordan dagen for fjellturen hadde vært: «En dag med klar, blå himmel». Det hun ikke forstod var at man kunne bli «klar av å gå i fjellet», altså «klar» i betydningen «sliten, utmattet». Selv om hun sukket litt over den lokale bruken, var jeg stolt over at læreren min, skolen og Sandnessjøen var nevnt på radioen.
Det er mange adjektiv som er verd å løfte fram. Jeg bor i Trondheim og sier ofte «svang» og «stugg». Mange har lurt på hva jeg har ment. Disse og andre adjektiv bruker jeg sjelden i skriftlige framstillinger. Jeg vet at når jeg bruker ogs som som «hannjkLåen» eller «stalljstien» vil det skape problemer. Selv et så hyppig ord som «beire» kan være vanskelig nok.
Det er bare når jeg er i Botn at jeg snakker om å «hæL se». Selv blir jeg omtalt som både «fisn» og «krøtjen», ikke så rart egentlig, for badevannet i Osen er langt fra «gLøsanes». Når jeg «sett i mak» og sere utover Botnfjorden «stilljmo åleinæ», er det like greit å holde seg på land. Da kan man se unge par spasere forbi. De flirer og har det «løyle», og både den ene og den andre kan beskrives som «jøger» og dittjen». De kan ogsså hende at rampen er der. «Uførdragele» kan de være, kanskje «trålljåt».
Hvis man ikke er «ommakreddj», kan man ta seg en tur utover langs fjorden, og er det tidlig nok på året, kan en finne måsegg som ikke er «strøypt».
Noen brukte hendene flittig var «gubbelert. Andre er mer «sæmåt» og mestrer ikke teknikken med «binnjestekken» så resultatet blir ganske «semmert». Det er i hvert fall «brennjsekkert».
Til slutt kommer en liten kviss med adjektiv som ikke brukes ofte i skrift: «apellæ, baLkåt, havan i trehus, hyddjeslaus, jåLåt, jåsåt, næppert, puskåt, samfængt, sunnjreven». Hvor mange av disse bruker barn og barnebarn?
Når man møter folks utenbygds fra, må en ofte legge om talemålet for å bli forstått. En bil stod fast i snøen, og jeg tilbød hjelp ved å si «Ska e sku?». Sjåføren så på meg, rådvill: «Ska? Sku?» Men da jeg løftet øyenbrynene, gjorde en armbevegelse og sa «Dytt?», var svaret «ja».
Det finnes ei lang rekke ord av typen «sku», altså ord som forstås av folk fra samme dialektområde som meg, men ikke av folk «utenfra».
Det er også en annen ting som binder disse ordene sammen: De brukes muntlig, men finnes sjelden og aldri i skrift. Riktignok finnes en form av «å sku» på nynorsk – «å skuve», men på bokmål eksisterer ikke dette verbet.
Dette fikk meg til å tenke, og det slo meg raskt hvor mange ord jeg har i mitt vokabular som ikke brukes i skrift. Disse ordene fant aldri sin plass i tekster vi skrev i skolen, på en måte ble de tredjesortering og holdt borte fra bokmålet som dominerte i alt av skriving og lesing.
Dette betyr ikke at ordene i seg selv var verdiløse, og mange av dem bruker jeg til daglig. Det gikk raskt å hente fram mer enn femti verb som var ekskludert fra skriftspråket vi lærte i skolen, og det kunne være interessant å ta leserne med på en liten tur i dette terrenget. Kanskje kan de også være grunnlag for en liten kviss/quiz der leserne spør innflyttere til Sandnessjøen eller egne barn eller barnebarn om hva de betyr, for eksempel «Sluttj å hæms mæ katto!» eller «No e dæ like før e lengsæ de ut!».
Barndommen var full av uskrevne ord. Før «snyn brånæ», «furæ» vi skaren. Når våren var det tid lek i skog og mark, og vi kunne «ajjer tulljing, grasser, hårrs (mæ små-ongan)» eller «hæm se» på unger fra andre nabolag som stod der «å jynæ», eller «gliræ» for å si det på en annen måte.
Det kunne bli tilløp til slåssing, og da hendte det at en «drefsæ åt» en stakkar eller «kjukæ» vedkommende mot bakken slik at han begynte å «sip» eller «skrik». Kanskje «gaulæ» han å høgt at det kom en voksen for å «lunnjs» den skyldige av gårde.
Når vi lekte «jømsel» gjaldt det å «stannj pal» slik at en ikke ble funnet, og hvis leken foregikk etter at det ble mørkt, kunne det hende at en ble skremt og kunne «røss i hållj». Av og til måtte en stille seg bak et tre for «å pillj», men hvis en virkelig måtte på do, måtte en «kreist» for å bli ferdig fort.
Noen bygde hytte i skogen. Da måtte en «stæL matrial» på en byggeplass, trekke ut spiker og «bænk» den før en tok til med bygginga. Ble dette kjedelig, var det morsommere å «dryl te» en fotball og «kjyl» den opp i vinkelen.
Var en ved sjøen, kunne en se at «dæ kralæ» med dassmort, og en kunne «flinnjter» og telle antall hopp. Andre ting kunne en bare «sletter» ut på sjøen. På regnværsdager lekte vi inne. Ble det mye støy, kunne vi få beskjed om å «sluttj å mollester, dæ bi før myttje gallauring!».
Hvis jentene var med og en kom nær nok, kunne en «kjett de» litt, og når en ble eldre ble det kanskje mulighet for både «å kjon» og «å gnu».
Når kvelden kom, måtte vi «gang» heim, og der stod ofte ho mammæ på trappa og skjentes fordi vi hadde vært ute og «ralljæ». Kveldsmaten stod klar og da først kunne en kjente at en nesten hadde «starvæ a». Og de som ikke hadde gjort leksene, satt og «staukæ» helt til de nesten «komnæ». De som ikke hadde lekser, kunne sette seg ned og «fetteler» med et puslespill før en måtte pusse tennene og «skøL» munnen.
Til slutt kommer en kviss med verb som generelt ikke brukes i skrift (stor L står for «tjukk L» i uttalen av ordene): Hva betyr «å bongeL, å bæmmeL, å dæmmeL, å dævveL, å fekkeL, å gokkeL, å køL, å kåkkeL, å mokkeL, å nævvel, å prekkeL, å skoffeL, å skoL sjetthus, å skonkeL, å vævveL». Og hva ville du skrive hvis du trengte å bruke disse ordene i en tekst?
Egentlig bør en skryte hemningsløst av elever fra Helgeland når det gjelder den innsatsen de gjør i norsktimene på skolen. Skrytet gjelder også oss voksne som er ferdige med skolen. Hvorfor så mye skryt?
For det første må elevene lære oss å omsette språklyder til skrifttegn. Det er vanskelig for én lyd kan ha både én, to og tre bokstaver, jf. «si, sju, skjær». Noen ganger måtte vi skrive bokstaver som ikke hadde noen lyd knyttet til seg som «hjemme, gjemme». Og toppen av alt, noen bokstaver står for flere lyder, se på o’en i «god, godt».
For det andre må en lære å oversette ord fra dialekt til bokmål. «Fesk» skal skrives «fisk», og «fæst» skal skrives «fest». Ord må bøyes riktig også. Er det snakk om «to fæstæ», måtte en skrive «to fester».
For det tredje lærte en at mange av ordene våre ikke hadde noen plass i skriftspråket i det hele tatt. Å skrive «bi» er feil. Skriv «bli» eller blir», sa læreren. (Nynorsk har formen «bid» – «Det bid nok å gå bra», men i Sandnessjøen er det bokmål.) Noen ganger er lærerne som ukyndige. Formen «ist» er faktisk godkjent på bokmål: «Han ist ikke å gå» er fullt lovlig.
Vi måtte innrette oss etter en standard med opphav på Øst landet. De fleste som bor der, har for sin del en kortere vei til skriftspråket. Kona mi og jeg var en gang på en klesbutikk på Karl Johan og skulle se etter klær til en «glønnjt». «Grønt?» sa ekspeditøren. «Et sekund senere stod han der med grønne gensere og bukser.
Det er så mange av de dagligdagse ordene som aldri kom inn i det gode selskap av ordbøker og ordlister, og det var generelt lite fokus på slikt i norsktimene. Når vi i min barndom holdt noen for «aletjo» visste alle hva det var snakk om. I byen var det en og annen «slaur» eller «slodose» å se. Fra tid til annen kunne de være «rusan», men som regel var de ufarlige. En og annen var litt «skjettnsam» og hadde sikkert «gråkakk punnj øran», kanskje så mye at en «kattvask» eller «skjettkarivask» knapt hadde hjulpet.
Noen ganger når det regnet, lektevi inne, kom de voksne «i eningen» og ropte: «Kyssjt mæ dåkker! Førr en alo!». Til slutt ble vi sendt ut. Der kunne det være en «maLvase» med andre unger. Etter regnet kunne de minste hoppe i «tjønnje» så «skjettdyo» skvatt. De voksne var ikke med ut, men vi ble formanet til ikke å ligge på bakken om våren. Da kunne vi nemlig få «joLdunnjs».
Når en voksen fortalte om «blodtrøsken» som var resultat av uvøren snekring, var det ingen som trengte å spørre hva det var. Om noen ville vite «me´an te auårstøæ» kunne de som var lommekjent, bare «sjå opp i loktæ». Vi ungene visste ikke «en døyt» om slikt.
Når vi kom inn om kvelden kunne brøddeigen stå klar, og da vanket det gjerne varm «klappækakæ» med sirup. Den som åt for mye, kunne få som attest at han var et «ofylljfat», og ble forberedt på at det kunne bli «brøstve» i løpet av natta.
Hadde vi vært «rampåt» og gjort «gærnskap», skulle det også gjøres opp for. Det enkleste var å høre at de voksne «skjennjtes» og ba oss om å «skjæmmes», men i grove tilfeller kunne en få «en drefs mæ kopptvogo over fengran» eller «ris på rævæ».
Middagene i min barndom var greie, men ikke alt var «etanes». Jeg fikk fort «stuggo» på «kLubb og fettj» og «boknæfesk», mens «bLopannjkakæ» og «kjelost» var favoritter. Om lørdagene vanket det «gåttje» i en spisspose. Der kunne det være nok «svitmint» til ei skikkelig «kjukæ».
De voksne satte sin ære i at vi ungene var rene og pene, og kvelden når vi la oss med nypussede tenner og duftende av Dr. Greves barnesebe, vanket det en «godkjæke» etter «kvelljsbønnæ».
Hvor mange av ordene i hermetegn» har overlevd? Kanskje de kan være grunnlag for en spørsmålsrunde rundt middagsbordet. Hva kan barn og barnebarn av dette?
Lørdagskryssordoppgavemakeren bad meg finne et synonym til ”lærer”. Svaret viste seg å være ”rødblyantanvendingsfagperson”. Løsningsordet skulle skrives loddrett, og lenge stod tomme ruter gapende og ventet på sin bokstav. Det var nødvendig å gå omveier før svaret stod der, men da virket det i grunnen innlysende. Da var det verre med et ord på 14 bokstaver som skulle bety det samme som ”gjerde”. ”Skigard” var for kort, ”plankegjerde” for nærliggende. Løsningsordet ville ikke avsløre seg før de fleste loddrette ordene som krysser det var klare. Plutselig stod løsningen der: ”stridsepletema”. Tommelen opp for kryssordforfatteren. Dette var et av de mer utspekulerte løsningsordene.
Noen ganger har jeg lurt på om det ikke kunne stilles en diagnose på kryssordforfatterens sinnstilstand i gjerningsøyeblikket. Jeg føler meg i alle fall plaget i jakten på et synonym for ”selger” der svaret viser seg å være ”avhendingsprosessdeltager”. Det må være kvaliteter ved forfatterne siden de makter å engasjere titusener i jakt på mer eller mindre kjente løsningsord. Lørdagsengasjementet som oppklaringsansvarlig orddetektiv har mange ganger ført til utsettelse av andre og mer nødvendige aktiviteter.
Kryssord er trolig den mest populære ordleken i verden. Underlig nok har de en ganske kort historie. De første dukket opp i barne- og ukeblad i England på 1800-tallet. De var enkle magiske kvadratene. En norsk parallell vil være å plassere bokstavene E,L,S,V i et kvadrat på 4×4 ruter slik at de danner ord både vannrett og loddrett. Ordene LESE, ESEL, SELE, ELEV skrevet rett under hverandre gir en slik mulighet.
Det første ”ordkryss” ble publisert 21. desember 1913 i søndagsbilaget til avisen New York World. Forfatteren var den engelske journalisten Arthur Wynne. Det var utformet som en diamant, med andre ord et kvadrat vridd slik at hjørnene pekte opp og ned og til sidene. Kryssordet inneholdt ikke noen svarte felt. Stikkordene var oppgitt ved siden av. Løsningsordene var på tre, fire eller fem bokstaver, og et av dem var oppgitt – ”FUN” – moro.
Wynnes idé ble plukket opp av andre amerikanske aviser. Betegnelsen ble etter hvert endret til ”kryssord” og ti år etter premieren kunne man finne dem i de fleste amerikanske aviser. I de klassiske variantene er løsningsordene synonymer som ”unik : enestående” eller ord fra et saksområde: ”bryteuttrykk : nelson”. Alternativt jakter en på over-/underbegrep som ”handel : gatesalg”. Det finnes varianter hvor løsningen er en helt setning som slanger seg gjennom kryssordet. Mitt favorittkryssord prøver øyensynlig å tilføre det norske språket nye sammensatte ord.
Kryssordene fant sin vei til Europa. Det første engelske ble publisert i 1922, og ikke lenge etter dukket de opp i Norge, gjerne under navnet ”kryssordgåte”. I dag finnes de i aviser, ukeblad og egne kryssordblad for barn og voksne. Omfanget er fra mindre enn 50 ruter til påskekryssordenes to hele avissider.
Om det er fornuftig tidtrøyte? I alle fall skal det være helsebringende. Den australske forskeren Perry Bartlett, professor ved hjerneinstituttet ved universitet i Queensland, Australia hevder at mental og fysisk trening holder hjernen aktiv og stimulerer produksjonen av nye nerveceller. Han peker på tre aktiviteter som spesielt holder hjerne og kropp i form, nemlig kryssord, jogging og sex. Jeg er helt enig. ”Ukeavslutningsaktivitetsprogrammet” er ikke komplett uten kryssordet.
På en stolpe nedi veien står det to plakater. På den ene står det «Fest på lokalet på lørdag», på den andre «Fest på lokale’ på lørdag». Jeg vil dit hvor det er mest liv. Men hvor er det? Jeg er ikke tvil om hvor jeg vil dra.
På festen ytrer en person samme replikk med et par timers mellomrom: «Hvor er øle’ hen?» og «Hvor er ølet hen?» Hvilken av disse to ble ytret først? Det er heller ikke vanskelig å svare på det.
Det interessante her er at vi leser av stemningen ved hjelp av om apostrofen har erstattet en bokstav eller ikke. Når teksten blir lest høyt, er det ingen endringer knyttet til språklyder som sies. Det er ingen forskjell på «lokalet» og «lokale’ » eller «ølet» og «øle’ «. Signalene om feststemning og tidspunkt signaliseres ved ±apostrof. I talt språk ville dette ikke være observerbart. For å understreke forskjellen i innhold, måtte en ta andre virkemidler i bruk, for eksempel stemmekvalitet eller intonasjon.
Denne måten å markere ytringer på i skrift har en sterk effekt. Formen som replikken får, tegner et portrett av den som ytrer seg, og vi vet plutselig mye om taleren. Hvem er det som sier “rikti’, me’, huse’”, og hvem er det som sier “riktig, med, huset”. Her trekkes en mot karakteristikker som ±urban, ±utdannet og andre.
Finn Erik Vinje kaller dette fenomenet «øyedialekt», en betegnelse som jeg finner treffende. Det er først etter at en har sett og lest teksten, at en, er i stand til å trekke konklusjoner om personenes karakter bakgrunn. Dersom noen leser teksten høyt, er det ikke mulig å høre forskjell på “riktig/rikti’, med/me’, huset/huse’”.